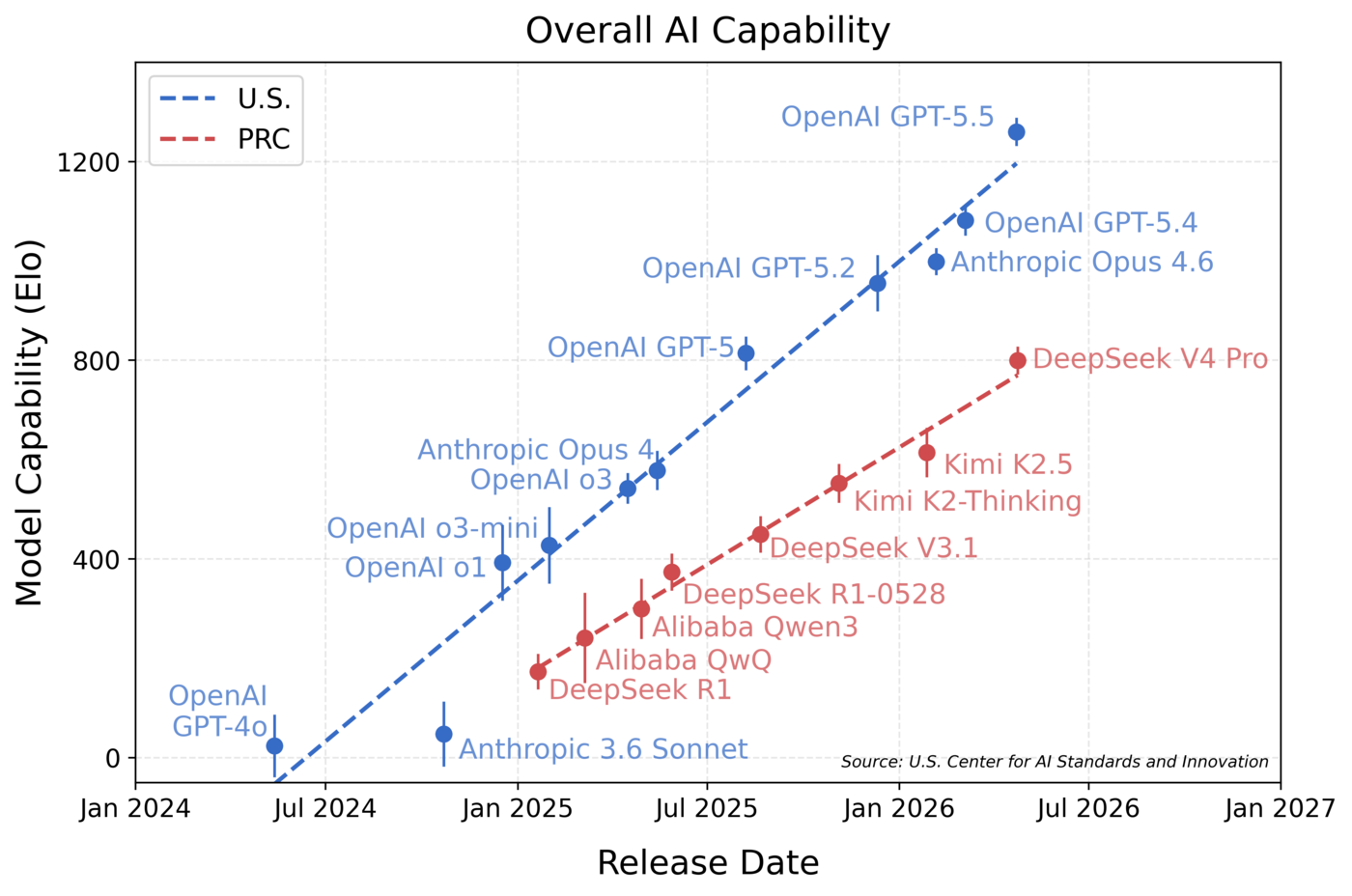
El Center for AI Standards and Innovation, integrado en NIST, ha publicado una evaluación de DeepSeek V4 Pro. El informe concluye que se trata del modelo chino más capaz evaluado por CAISI hasta la fecha, pero que sus capacidades agregadas se sitúan aproximadamente ocho meses por detrás de la frontera estadounidense. La evaluación cubre dominios como ciberseguridad, ingeniería de software, ciencias naturales, razonamiento abstracto y matemáticas.
Más allá de los benchmarks públicos
La parte más interesante del análisis es la diferencia entre los resultados declarados por DeepSeek y los obtenidos por CAISI en su propia batería de pruebas. El informe indica que, en evaluaciones reportadas por la propia compañía, DeepSeek V4 aparece cercano a modelos como Opus 4.6 o GPT-5.4. Sin embargo, en benchmarks no públicos o no incluidos en el informe técnico del desarrollador, CAISI observa un rendimiento más parecido al de GPT-5, publicado unos ocho meses antes.
El organismo utilizó pruebas en ciberseguridad, programación, razonamiento científico y matemático, incluyendo ARC-AGI-2 en versión semiprivada, CTF-Archive-Diamond y PortBench, una evaluación interna para tareas de ingeniería de software. También aplicó una metodología inspirada en Item Response Theory para comparar capacidades agregadas entre modelos. Esta aproximación intenta reducir la dependencia de benchmarks públicos, cada vez más expuestos a contaminación, optimización específica y selección interesada de métricas.
Coste, seguridad y competencia geopolítica
CAISI también destaca que DeepSeek V4 Pro es más eficiente en coste que otros modelos de capacidad similar en cinco de siete benchmarks comparables. Ese punto es relevante porque la competitividad de un modelo no depende solo de su puntuación máxima, sino del coste real de resolver tareas. Un modelo algo menos potente pero mucho más barato puede ser atractivo para empresas, desarrolladores y países con limitaciones de infraestructura.
La lectura estratégica es doble. Primero, la evaluación oficial refuerza la necesidad de mediciones independientes, especialmente cuando los modelos se convierten en activos económicos y geopolíticos. Segundo, muestra que China mantiene un ritmo competitivo en modelos abiertos o accesibles, aunque el liderazgo de frontera siga concentrado en laboratorios estadounidenses.
Para el mercado, el mensaje es prudente. DeepSeek V4 Pro no debería ser tratado como equivalente automático a los modelos frontera más recientes, pero tampoco como una alternativa marginal. Su combinación de capacidad, coste y apertura puede presionar precios y acelerar la adopción, sobre todo en organizaciones que priorizan eficiencia. Para reguladores y responsables de seguridad, la conclusión es aún más clara: medir bien se ha convertido en una infraestructura pública esencial para entender riesgos, dependencia tecnológica y capacidad real de los sistemas de IA.